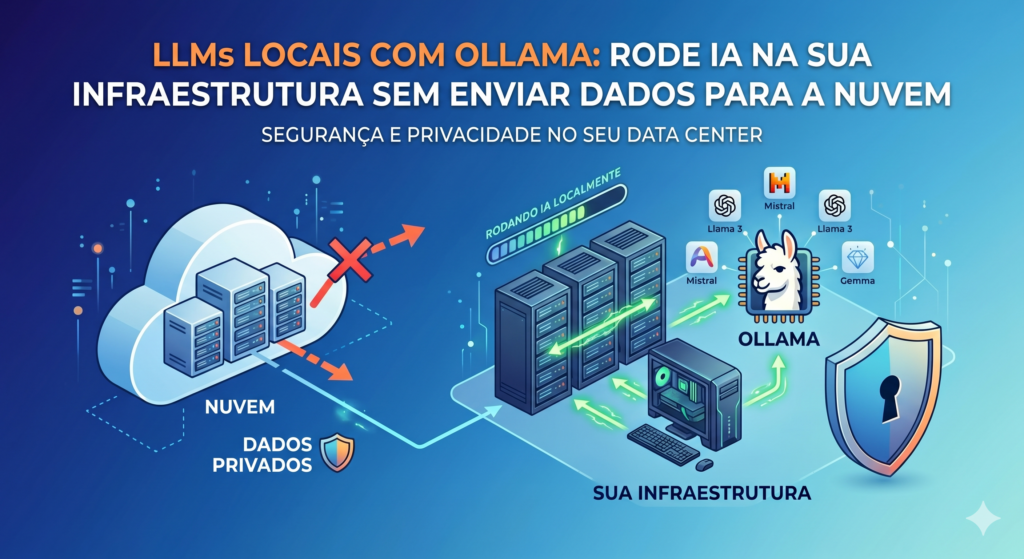
Uma das principais barreiras para adoção de IA em empresas que lidam com dados sensíveis é a preocupação com privacidade. O Ollama resolve isso — permite rodar modelos de linguagem de ponta 100% localmente, sem que nenhum dado saia da sua infraestrutura.
O que é o Ollama?
O Ollama é uma ferramenta open source que simplifica radicalmente a instalação e execução de LLMs em hardware local. Funciona como um gerenciador de modelos — similar ao Docker para containers, mas para modelos de IA. Com ele você pode rodar modelos como Llama 3.3, Mistral 7B, DeepSeek-R1 e Gemma 3.
Requisitos de hardware
| Modelo | Parâmetros | RAM mínima | GPU |
|---|---|---|---|
| Mistral 7B | 7B | 8 GB | Opcional |
| Llama 3.2 | 3B | 4 GB | Opcional |
| Llama 3.3 | 70B | 48 GB | Recomendada |
| DeepSeek-R1 | 7B | 8 GB | Opcional |
💡 Para PMEs sem GPU dedicada, os modelos de 7B rodam bem em servidores com 16–32 GB de RAM apenas com CPU. A velocidade é menor (2–5 tokens/segundo), mas suficiente para uso assíncrono.
1. Instalação
# Linux (Debian/Ubuntu)
curl -fsSL https://ollama.com/install.sh | sh
ollama --versionOu via Docker (recomendado para servidores de produção):
# docker-compose.yml
services:
ollama:
image: ollama/ollama:latest
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
volumes:
ollama_data:2. Baixar e rodar modelos
# Baixar Llama 3.2 (~2GB)
ollama pull llama3.2
# Baixar Mistral 7B (~4GB)
ollama pull mistral
# Iniciar chat interativo
ollama run llama3.23. API REST — integrar com aplicações
O Ollama expõe uma API REST compatível com a API da OpenAI:
curl http://localhost:11434/api/generate \
-d '{
"model": "llama3.2",
"prompt": "Explique o conceito de Zero Trust em 3 parágrafos.",
"stream": false
}'Compatibilidade direta com o OpenAI SDK — basta apontar para o endpoint local:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama"
)
response = client.chat.completions.create(
model="llama3.2",
messages=[{"role": "user", "content": "Resuma as principais CVEs de maio 2026"}]
)
print(response.choices[0].message.content)4. Open WebUI — interface para usuários não técnicos
O Open WebUI oferece uma interface similar ao ChatGPT que se conecta ao Ollama. Acesse http://seu-servidor:3000 após subir o container:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- open-webui_data:/app/backend/data5. Segurança — não expor o Ollama para a internet
Por padrão, o Ollama escuta em 0.0.0.0:11434. Em produção, restrinja para localhost e use um proxy reverso com autenticação para acesso remoto:
# /etc/systemd/system/ollama.service.d/override.conf
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"Conclusão
O Ollama democratizou o acesso a LLMs locais. Para empresas que lidam com dados sigilosos — contratos, dados de saúde, informações financeiras —, rodar IA on-premise não é mais uma opção cara e complexa. Com hardware modesto e 30 minutos de configuração, é possível ter um assistente de IA funcional que nunca envia um byte para fora da sua rede.
Referências
- Ollama. Ollama Documentation. Disponível em: ollama.com
- Open WebUI. Open WebUI Documentation. Disponível em: docs.openwebui.com
- Meta AI. Llama 3 Model Card. Disponível em: llama.meta.com


